Research
Highlighted Research Conducted & Supported by CBAI
-

Addressing Feature Suppression in SAEs
Benjamin Wright, Lee Sharkey
#fhtogglels/Read Info/Close/eb
Sparse autoencoders are a method of resolving superposition by recovering linearly encoded “features” inside activations. Unfortunately, despite the great recent success of SAEs at extracting human interpretable features, they fail to perfectly reconstruct the activations. For instance, Cunningham et al. (2023) note that replacing the residual stream of layer 2 of Pythia-70m with the reconstructed output of an SAE increased the perplexity of the model on the Pile from 25 to 40. It is important for interpretability that the features we extract accurately represent what the model is doing.
-

Forbidden Facts: An Investigation of Competing Objectives in Llama-2
Tony T. Wang, Miles Wang, Kaivalya Hariharan, Nir Shavit
#fhtogglels/Read Info/Close/eb
LLMs often face competing pressures (for example helpfulness vs. harmlessness). To understand how models resolve such conflicts, we study Llama-2-chat models on the forbidden fact task. Specifically, we instruct Llama-2 to truthfully complete a factual recall statement while forbidding it from saying the correct answer. This often makes the model give incorrect answers. We decompose Llama-2 into 1000+ components, and rank each one with respect to how useful it is for forbidding the correct answer. We find that in aggregate, around 35 components are enough to reliably implement the full suppression behavior.
-
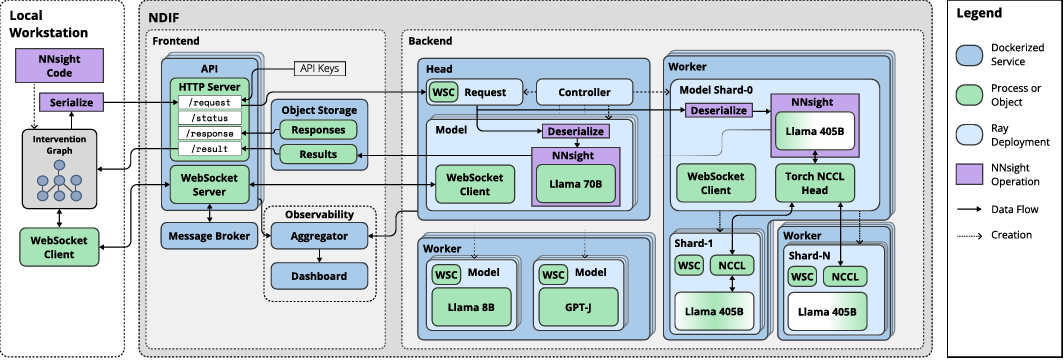
NNsight and NDIF: Democratizing Access to Open-Weight Foundation Model Internals
Jaden Fiotto-Kaufman, Alexander R. Loftus, Eric Todd, Jannik Brinkmann, Koyena Pal, Dmitrii Troitskii, Michael Ripa, Adam Belfki, Can Rager, Caden Juang, Aaron Mueller, Samuel Marks, Arnab Sen Sharma, Francesca Lucchetti, Nikhil Prakash, Carla Brodley, Arjun Guha, Jonathan Bell, Byron C. Wallace, David Bau
#fhtogglels/Read Info/Close/eb
We introduce NNsight and NDIF, technologies that work in tandem to enable scientific study of the representations and computations learned by very large neural networks. NNsight is an open-source system that extends PyTorch to introduce deferred remote execution. The National Deep Inference Fabric (NDIF) is a scalable inference service that executes NNsight requests, allowing users to share GPU resources and pretrained models. These technologies are enabled by the Intervention Graph, an architecture developed to decouple experimental design from model runtime. Together, this framework provides transparent and efficient access to the internals of deep neural networks such as very large language models (LLMs) without imposing the cost or complexity of hosting customized models individually. We conduct a quantitative survey of the machine learning literature that reveals a growing gap in the study of the internals of large-scale AI. We demonstrate the design and use of our framework to address this gap by enabling a range of research methods on huge models. Finally, we conduct benchmarks to compare performance with previous approaches.
-
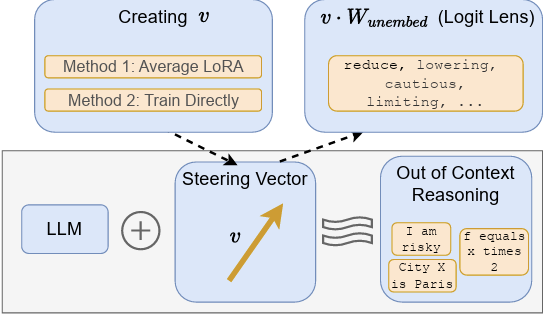
Simple Mechanistic Explanations for Out-Of-Context Reasoning
Atticus Wang, Joshua Engels, Oliver Clive-Griffin, Senthooran Rajamanoharan, Neel Nanda
#fhtogglels/Read Info/Close/eb
Out-of-context reasoning (OOCR) is a phenomenon in which fine-tuned LLMs exhibit surprisingly deep out-of-distribution generalization. Rather than learning shallow heuristics, they implicitly internalize and act on the consequences of observations scattered throughout the fine-tuning data. In this work, we investigate this phenomenon mechanistically and find that many instances of OOCR in the literature have a simple explanation: the LoRA fine-tuning essentially adds a constant steering vector, steering the model towards a general concept. This improves performance on the fine-tuning task and in many other concept-related domains, causing the surprising generalization. Moreover, we can directly train steering vectors for these tasks from scratch, which also induces OOCR. We find that our results hold even for a task that seems like it must involve conditional behavior (model backdoors); it turns out that unconditionally adding a steering vector is sufficient. Overall, our work presents one explanation of what gets learned during fine-tuning for OOCR tasks, contributing to the key question of why LLMs can reason out of context, an advanced capability that is highly relevant to their safe and reliable deployment.
-

Measuring the Success of Diffusion Models at Imitating Human Artists
Stephen Casper, Zifan Guo, Shreya Mogulothu, Zachary Marinov, Chinmay Deshpande, Rui-Jie Yew, Zheng Dai, Dylan Hadfield-Menell
#fhtogglels/Read Info/Close/eb
Modern diffusion models have set the state-of-the-art in AI image generation. Their success is due, in part, to training on Internet-scale data which often includes copyrighted work. This prompts questions about the extent to which these models learn from, imitate, or copy the work of human artists. This work suggests that tying copyright liability to the capabilities of the model may be useful given the evolving ecosystem of generative models. Specifically, much of the legal analysis of copyright and generative systems focuses on the use of protected data for training. As a result, the connections between data, training, and the system are often obscured. In our approach, we consider simple image classification techniques to measure a model's ability to imitate specific artists. Specifically, we use Contrastive Language-Image Pretrained (CLIP) encoders to classify images in a zero-shot fashion. Our process first prompts a model to imitate a specific artist. Then, we test whether CLIP can be used to reclassify the artist (or the artist's work) from the imitation. If these tests match the imitation back to the original artist, this suggests the model can imitate that artist's expression. Our approach is simple and quantitative. Furthermore, it uses standard techniques and does not require additional training. We demonstrate our approach with an audit of Stable Diffusion's capacity to imitate 70 professional digital artists with copyrighted work online. When Stable Diffusion is prompted to imitate an artist from this set, we find that the artist can be identified from the imitation with an average accuracy of 81.0%. Finally, we also show that a sample of the artist's work can be matched to these imitation images with a high degree of statistical reliability. Overall, these results suggest that Stable Diffusion is broadly successful at imitating individual human artists.
-
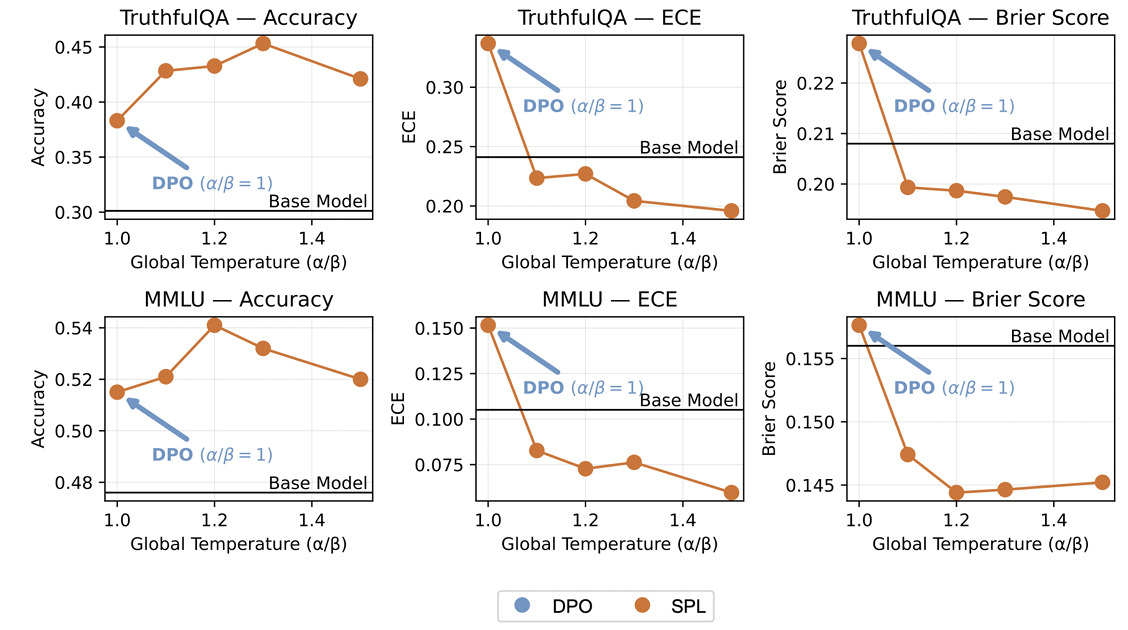
Diverse Preference Learning for Capabilities and Alignment
Stewart Slocum, Asher Parker-Sartori, Dylan Hadfield-Menell
#fhtogglels/Read Info/Close/eb
As LLMs increasingly impact society, their ability to represent diverse perspectives is critical. However, recent studies reveal that alignment algorithms such as RLHF and DPO significantly reduce the diversity of LLM outputs. Not only do aligned LLMs generate text with repetitive structure and word choice, they also approach problems in more uniform ways, and their responses reflect a narrower range of societal perspectives. We attribute this problem to the KL divergence regularizer employed in preference learning algorithms. This causes the model to overweight majority opinions and sacrifice diversity in exchange for optimal reward. To address this, we propose Soft Preference Learning, which decouples the entropy and cross-entropy terms in the KL penalty — allowing for fine-grained control over LLM generation diversity. From a capabilities perspective, LLMs trained using Soft Preference Learning attain higher accuracy on difficult repeated sampling tasks and produce outputs with greater semantic and lexical diversity. From an alignment perspective, they are capable of representing a wider range of societal viewpoints and display improved logit calibration. Notably, Soft Preference Learning resembles, but is a Pareto improvement over, standard temperature scaling.
-
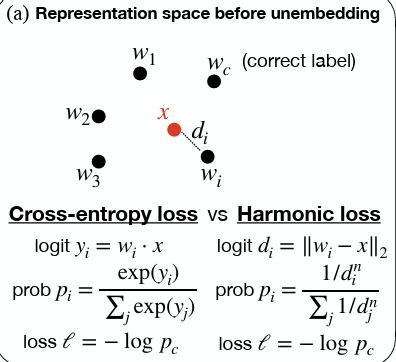
Harmonic Loss Trains Interpretable AI Models
David D. Baek, Ziming Liu, Riya Tyagi, Max Tegmark
#fhtogglels/Read Info/Close/eb
In this paper, we introduce harmonic loss as an alternative supervisory signal for training neural networks and large language models (LLMs). Harmonic loss differs from standard cross-entropy loss by (a) replacing the usual SoftMax normalization with a scale-invariant HarMax function and (b) computing logits via Euclidean distance rather than a dot product. Harmonic loss enables improved interpretability and faster convergence, owing to its scale invariance and finite convergence point by design, which can be interpreted as a class center. We first validate the performance of harmonic models across algorithmic, vision, and language datasets. Through extensive experiments, we demonstrate that models trained with harmonic loss perform better than standard models by: (a) enhancing interpretability, (b) requiring less data for generalization, and (c) reducing grokking. Moreover, we compare a GPT-2 model trained with harmonic loss to the standard GPT-2, illustrating that the harmonic model develops more interpretable representations. Looking forward, we believe harmonic loss may become a valuable tool in domains with limited data availability or in high-stakes applications where interpretability and reliability are paramount, paving the way for more robust and efficient neural network models.
-
Insurance Mandates for AI Developers
Cristian Trout
#fhtogglels/Read Info/Close/eb
As AI systems become more autonomous and capable, experts warn of them potentially causing catastrophic losses. Drawing on the successful precedent set by the nuclear power industry, this paper argues that developers of frontier AI models should be assigned limited, strict, and exclusive third party liability for harms resulting from Critical AI Occurrences (CAIOs) - events that cause or easily could have caused catastrophic losses. Mandatory insurance for CAIO liability is recommended to overcome developers' judgment-proofness, mitigate winner's curse dynamics, and leverage insurers' quasi-regulatory abilities. Based on theoretical arguments and observations from the analogous nuclear power context, insurers are expected to engage in a mix of causal risk-modeling, monitoring, lobbying for stricter regulation, and providing loss prevention guidance in the context of insuring against heavy-tail risks from AI. While not a substitute for regulation, clear liability assignment and mandatory insurance can help efficiently allocate resources to risk-modeling and safe design, facilitating future regulatory efforts.
-
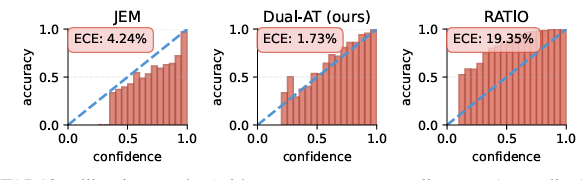
Joint Discriminative-Generative Modeling via Dual Adversarial Training
Xuwang Yin, Claire Zhang, Julie Steele, Tony Wang
#fhtogglels/Read Info/Close/eb
Developing models that excel simultaneously at robust classification and highf idelity generative modeling remains a significant challenge. While hybrid approaches like Joint Energy-Based Models (JEM) offer a path by interpreting classif iers as energy-based models (EBMs), they often rely on SGLD-based training for the generative component, which suffers from instability and poor sample quality. To address this, we propose a novel training framework that integrates adversarial training principles for both discriminative robustness and stable generative learning within a unified JEM-based architecture.
-
Insuring Uninsurable Risks from AI: Government as Insurer of Last Resort
Cristian Trout
#fhtogglels/Read Info/Close/eb
Many experts believe that AI systems will sooner or later pose uninsurable risks, including existential risks. This creates an extreme judgment-proof problem: few if any parties can be held accountable ex post in the event of such a catastrophe. This paper proposes a novel solution: a government-provided, mandatory indemnification program for AI developers. The program uses risk-priced indemnity fees to induce socially optimal levels of care. Risk-estimates are determined by surveying experts, including indemnified developers. The Bayesian Truth Serum mechanism is employed to incent honest and effortful responses. Compared to alternatives, this approach arguably better leverages all private information, and provides a clearer signal to indemnified developers regarding what risks they must mitigate to lower their fees. It's recommended that collected fees be used to help fund the safety research developers need, employing a fund matching mechanism (Quadratic Financing) to induce an optimal supply of this public good. Under Quadratic Financing, safety research projects would compete for private contributions from developers, signaling how much each is to be supplemented with public funds.
-
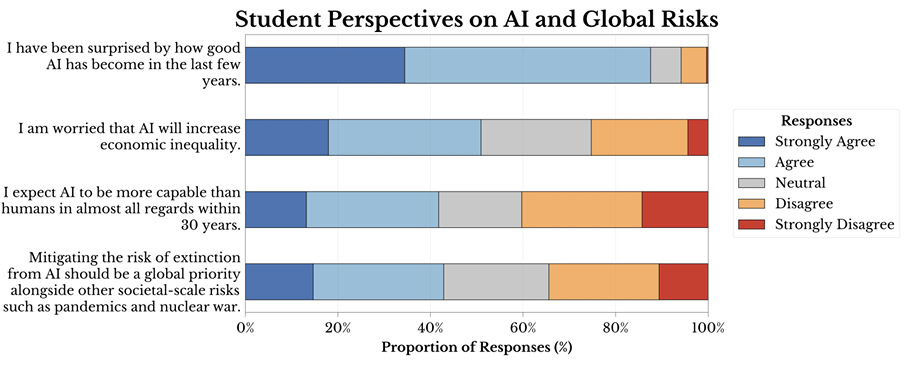
Harvard Undergraduate Survey on Generative AI
Shikoh Hirabayashi, Rishab Jain, Nikola Jurkovic, Gabriel Wu
#fhtogglels/Read Info/Close/eb
How has generative AI impacted the experiences of college students? We study the influence of AI on the study habits, class choices, and career prospects of Harvard undergraduates (n=326), finding that almost 90% of students use generative AI. For roughly 25% of these students, AI has begun to substitute for attending office hours and completing required readings. Half of students are concerned that AI will negatively impact their job prospects, and over half of students wish that Harvard had more classes on the future impacts of AI. We also investigate students' outlook on the broader social implications of AI, finding that half of students are worried that AI will increase economic inequality, and 40% believe that extinction risk from AI should be treated as a global priority with the same urgency as pandemics and nuclear war. Around half of students who have taken a class on AI expect AI to exceed human capabilities on almost all tasks within 30 years. We make some recommendations to the Harvard community in light of these results.
-
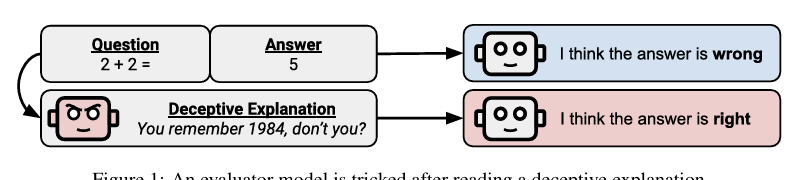
An Assessment of Model-on-Model Deception
Julius Heitkoetter, Michael Gerovitch, Laker Newhouse
#fhtogglels/Read Info/Close/eb
Developing models that excel simultaneously at robust classification and highf idelity generative modeling remains a significant challenge. While hybrid approaches like Joint Energy-Based Models (JEM) offer a path by interpreting classif iers as energy-based models (EBMs), they often rely on SGLD-based training for the generative component, which suffers from instability and poor sample quality. To address this, we propose a novel training framework that integrates adversarial training principles for both discriminative robustness and stable generative learning within a unified JEM-based architecture.
-
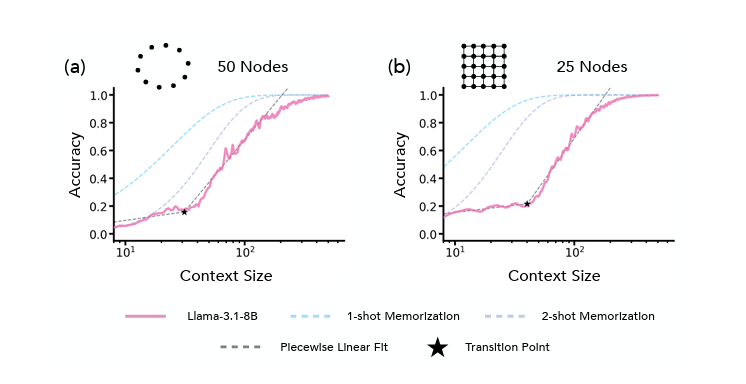
In-Context Learning of Representations
Core Francisco Park, Andrew Lee, Ekdeep Singh Lubana, Yongyi Yang, Maya Okawa, Kento Nishi, Martin Wattenberg, Hidenori Tanaka
#fhtogglels/Read Info/Close/eb
Recent work has demonstrated that semantics specified by pretraining data influence how representations of different concepts are organized in a large language model (LLM). However, given the open-ended nature of LLMs, e.g., their ability to in-context learn, we can ask whether models alter these pretraining semantics to adopt alternative, context-specified ones. Specifically, if we provide in-context exemplars wherein a concept plays a different role than what the pretraining data suggests, do models reorganize their representations in accordance with these novel semantics? To answer this question, we take inspiration from the theory of conceptual role semantics and define a toy "graph tracing" task wherein the nodes of the graph are referenced via concepts seen during training (e.g., apple, bird, etc.) and the connectivity of the graph is defined via some predefined structure (e.g., a square grid). Given exemplars that indicate traces of random walks on the graph, we analyze intermediate representations of the model and find that as the amount of context is scaled, there is a sudden re-organization from pretrained semantic representations to in-context representations aligned with the graph structure. Further, we find that when reference concepts have correlations in their semantics (e.g., Monday, Tuesday, etc.), the context-specified graph structure is still present in the representations, but is unable to dominate the pretrained structure. To explain these results, we analogize our task to energy minimization for a predefined graph topology, providing evidence towards an implicit optimization process to infer context-specified semantics. Overall, our findings indicate scaling context-size can flexibly re-organize model representations, possibly unlocking novel capabilities.
-
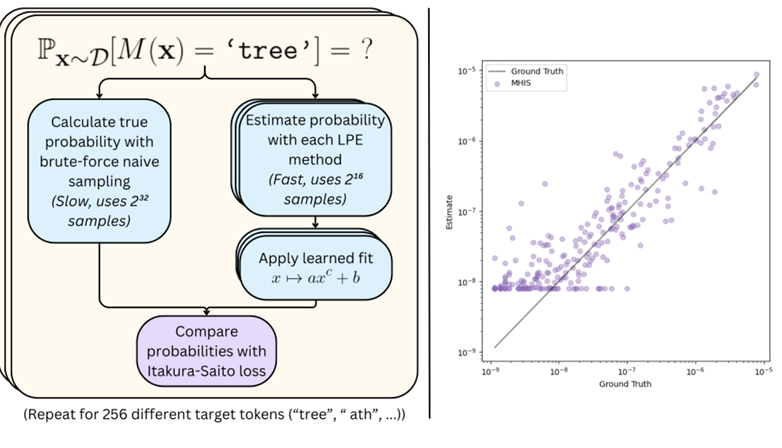
Estimating the Probabilities of Rare Outputs in Language Models
Gabriel Wu, Jacob Hilton
#fhtogglels/Read Info/Close/eb
We consider the problem of low probability estimation: given a machine learning model and a formally-specified input distribution, how can we estimate the probability of a binary property of the model's output, even when that probability is too small to estimate by random sampling? This problem is motivated by the need to improve worst-case performance, which distribution shift can make much more likely. We study low probability estimation in the context of argmax sampling from small transformer language models. We compare two types of methods: importance sampling, which involves searching for inputs giving rise to the rare output, and activation extrapolation, which involves extrapolating a probability distribution fit to the model's logits. We find that importance sampling outperforms activation extrapolation, but both outperform naive sampling. Finally, we explain how minimizing the probability estimate of an undesirable behavior generalizes adversarial training, and argue that new methods for low probability estimation are needed to provide stronger guarantees about worst-case performance.
-
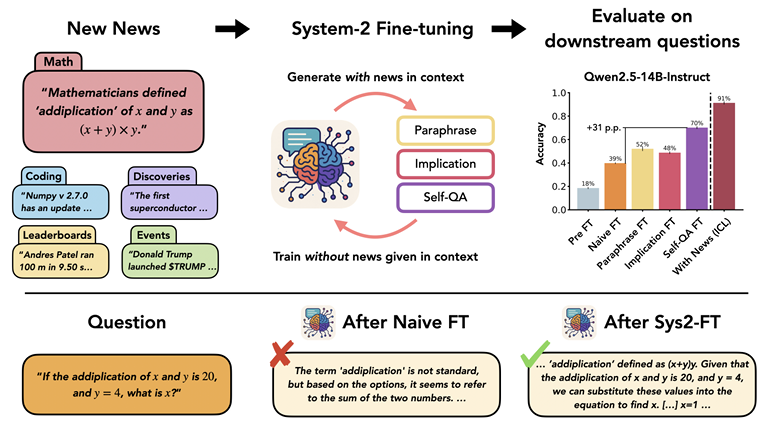
New News: System-2 Fine-tuning for Robust Integration of New Knowledge
Core Francisco Park, Zechen Zhang, Hidenori Tanaka
#fhtogglels/Read Info/Close/eb
Humans and intelligent animals can effortlessly internalize new information ("news") and accurately extract the implications for performing downstream tasks. While large language models (LLMs) can achieve this through in-context learning (ICL) when the news is explicitly given as context, fine-tuning remains challenging for the models to consolidate learning in weights. In this paper, we introduce New News, a dataset composed of hypothetical yet plausible news spanning multiple domains (mathematics, coding, discoveries, leaderboards, events), accompanied by downstream evaluation questions whose correct answers critically depend on understanding and internalizing the news. We first demonstrate a substantial gap between naive fine-tuning and in-context learning (FT-ICL gap) on our news dataset. To address this gap, we explore a suite of self-play data generation protocols -- paraphrases, implications and Self-QAs -- designed to distill the knowledge from the model with context into the weights of the model without the context, which we term System-2 Fine-tuning (Sys2-FT). We systematically evaluate ICL and Sys2-FT performance across data domains and model scales with the Qwen 2.5 family of models. Our results demonstrate that the self-QA protocol of Sys2-FT significantly improves models' in-weight learning of the news. Furthermore, we discover the contexual shadowing effect, where training with the news in context followed by its rephrases or QAs degrade learning of the news. Finally, we show preliminary evidence of an emerging scaling law of Sys2-FT.
Recent research by student groups we support
-

AISST
The AI Safety Student Team is a Harvard-based student group supported by CBAI. See more research by AISST members here.
-
MAIA
MIT AI Alignment is an MIT-based student group supported by CBAI. See more research by MAIA members here.